
머신러닝 학습절차: 문제정의 → 데이터전처리 → 학습 → 평가
1. 문제정의
내가 해결하고자 하는 문제가 무엇인지 이해하고, 어떤 목표를 달성하고 싶은지 정의하는 단계
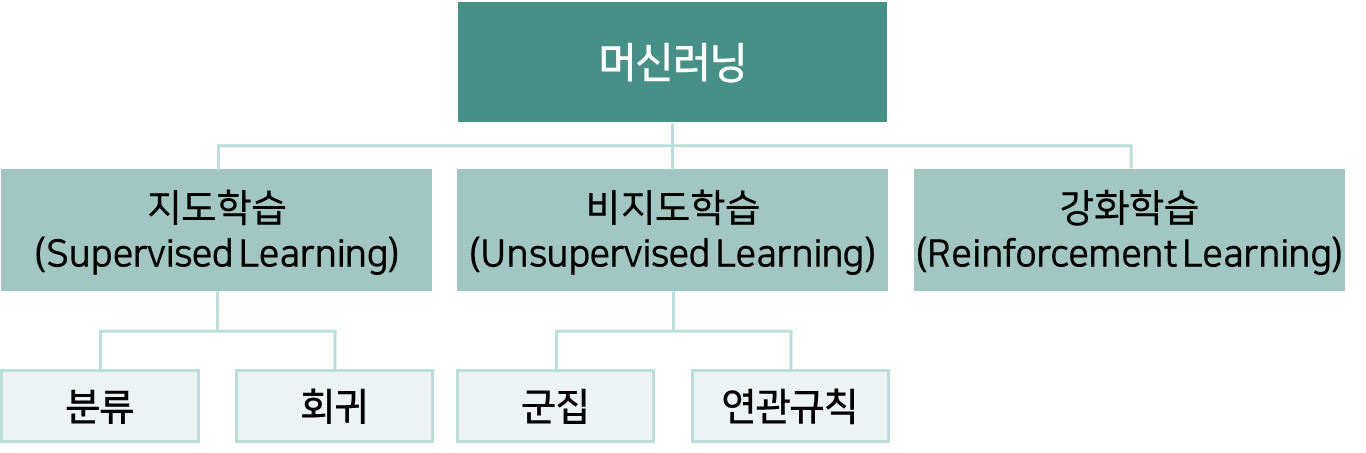
지도학습은 학습데이터에 레이블이 있는 형태로 진행한다.
- 레이블값이 범주형 데이터, 즉 A타입, B타입, C타입 같이 범주로 구성되어있고 범주형 데이터를 예측하기 위한 문제를 ‘분류 문제’라고 한다.
💡 특히 범주 유형이 성공/실패 같이 두가지만 존재하는 문제를 “이진분류”라고 한다.
- 레이블 값이 범주형 데이터가 아닌 연속된 실수형인 지도학습의 유형을 ‘회귀 문제’라고 한다. 부동산 가격, 주식 가격등 수치를 예측하는 문제는 회귀 문제로 정의하고 머신러닝을 수행한다.
비지도학습은 지도학습과 다르게 학습 데이터에 레이블이 존재하지 않는다.
- 분류: 그룹이 무엇인지(ex 세모, 네모) 알고 있다.
- 군집: 그룹이 무엇인지 알지 못한다(ex 그룹1, 그룹2)
⇒ 어떤 유형으로 문제를 정의 했는냐에 따라 학습과정에서 사용할 수 있는 알고리즘과 데이터 전처리 방법에 차이가 있다.
2. 데이터 전처리
⇒ 일반적으로 데이터 전처리는 데이터 정제, 변환, 축소 등 머신러닝을 수행하기 전에 데이터 형태를 변환시키는 작업을 의미한다.
- 데이터 탐색(EDA)
- ⇒ 수집된 데이터를 이해하는 과정
탐색적 데이터 분석이란 분석할 데이터에 직관을 얻기 위해 데이터 시각화 및 데이터 요약 정보를 활용하여 데이터 분포를 이해하는 과정
단순히 하나하나 피처를 확인해보는 것이 아니라 데이터의 주요 통계 지표나 시각화 기법을 사용하여 전반적인 데이터의 형태와 분포를 이해한다.
- 데이터 정제 (Data Cleansing)결측치는 학습 모델 처리 이전에 반드시 제거를 해야한다.반면 컬럼의 대부분의 값이 채워져 있지만 5% 미만의 일부 값만 비워져있는 상태라면, 결측치가 포함된 로우는 삭제하고 분석을 진행한다.
- 특정 컬럼의 50% 이상의 값이 결측치라면 해당 컬럼은 데이터분석에서 제거하는 것이 보통이다.
- 데이터 정제는 값을 변환하거나 불필요한 데이터를 제거하는 과정이다.
- 데이터 분할(Data Split)
- 데이터 정제까지 완료되면 → 학습용 데이터와 테스트용 데이터로 분할하는 작업을 진행한다.
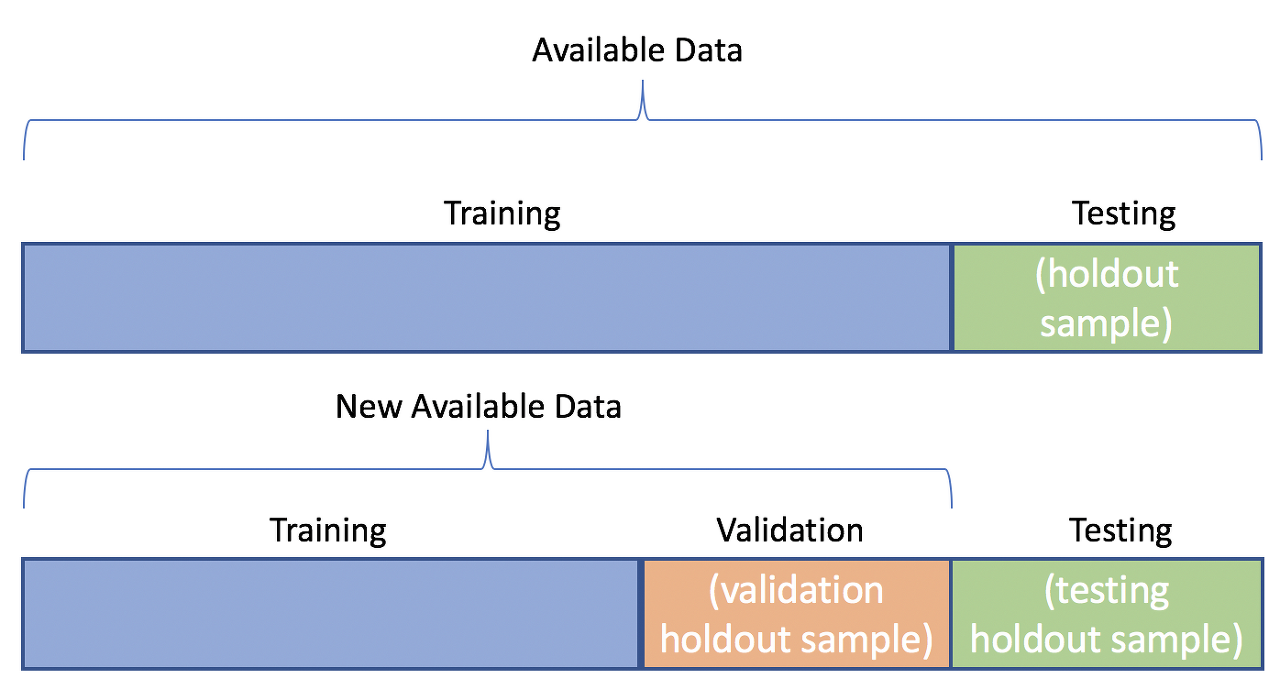
학습용 데이터셋과 테스트용 데이터셋의 비율은 일반적으로 7:3 또는 8:2 비율로 나누어 사용한다.
3. 데이터 학습
데이터 분할까지 완료가 되면 학습을 시켜야한다.
<aside> 💡 학습모델.fit(독립변수 X, 종속변수 y)
</aside>
⇒ 인자로 사용하는 독립변수 X와 y는 학습용 데이터 셋이다.
- 학습모델: 정제된 데이터를 사용하여 주어진 문제를 해결할 수 있는 알고리즘을 의미한다.
- 의사결정 나무(Decision Tree)최종 결과값을 얻어내기 위해 의사결정 과정을 가지로 만들어가며 진행한다.
- 붓꽃(iris)데이터 셋을 이용하여 3개의 품종을 분류하는 의사결정 나무를 생성
- 붓꽃데이터셋은 꽃받침 길이, 너비, 꽃잎 길이와 너비 4개의 특징 데이터에 따른 품종을 구분한 데이터로 총 150개 값이 존재
- 분류모델 또는 회귀모델로 사용하는 지도학습 기반의 알고리즘
- 의사결정나무의 학습 과정의사결정 나무는 최적의 분기 조건을 찾기 위해 분류된 값의 불순도가 낮아지도록 조건을 설정한다.
- 의사결정나무 과정에서 학습이란 최적의 분기문을 만들기 위한 의사결정 조건을 찾고 조건에 따라 나무를 생성해 나가는 과정
4. 데이터 평가
머신러닝 모델을 평가하는 방법은 기본적으로 모델을 통해서 예측한 값과 실제 값이 얼마나 일치하는지를 계산하여 판단한다.
⇒ 이때 사용하는 데이터는 데이터 셋이다. 학습 데이터셋은 모델을 학습하는 과정에서 이미 충분히 살펴본 값이기 때문에, 평가 과정에서는 사용하지 않는다.
분류 모델의 성능을 평가하기 위한 가장 기본적인 방법은 **정확도(Accuracy)**이다.
Accuracy(정확도)
모델이 전체 문제 중에서 정답을 맞춘 비율이다.
하지만 데이터가 불균형할 때(ex) positive:negative=9:1)는 Accuracy만으로 제대로 분류했는지는 알 수 없기 때문에 Recall과 Precision을 사용한다.
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
Precision(정밀도) = PPV(Positive Predictive Value)
모델이 positive라고 예측한 것들 중에서 실제로 정답이 positive인 비율이다.
실제 정답이 negative인 데이터를 positive라고 잘못 예측하면 안 되는 경우에 중요한 지표가 될 수 있다.
Precision을 높이기 위해선 FP(모델이 positive라고 예측했는데 정답은 negative인 경우)를 낮추는 것이 중요하다.
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
Recall(재현율) = Sensitivity(민감도) = TPR(True Positive Rate)
실제로 정답이 positive인 것들 중에서 모델이 positive라고 예측한 비율이다.
실제 정답이 positive인 데이터를 negative라고 잘못 예측하면 안 되는 경우에 중요한 지표가 될 수 있다.
Recall를 높이기 위해선 FN(모델이 negative라고 예측했는데 정답이 positive인 경우)을 낮추는 것이 중요하다.
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
F1 score
Recall과 Precision의 조화평균이다.
Recall과 Precision은 상호 보완적인 평가 지표이기 때문에 F1 score를 사용한다.
Precision과 Recall이 한쪽으로 치우쳐지지 않고 모두 클 때 큰 값을 가진다.
0 ~ 1 사이의 값을 가지며, 1에 가까울수록 좋다.
'✨Data Science > machine learning' 카테고리의 다른 글
| 머신러닝 분류 모델 성능평가 (0) | 2023.05.11 |
|---|---|
| <머신러닝> train 데이터와 test 데이터 (0) | 2023.05.09 |
| <머신러닝> 기본 (0) | 2023.05.09 |
| 넘파이/ 맷플롯립 (0) | 2023.04.18 |